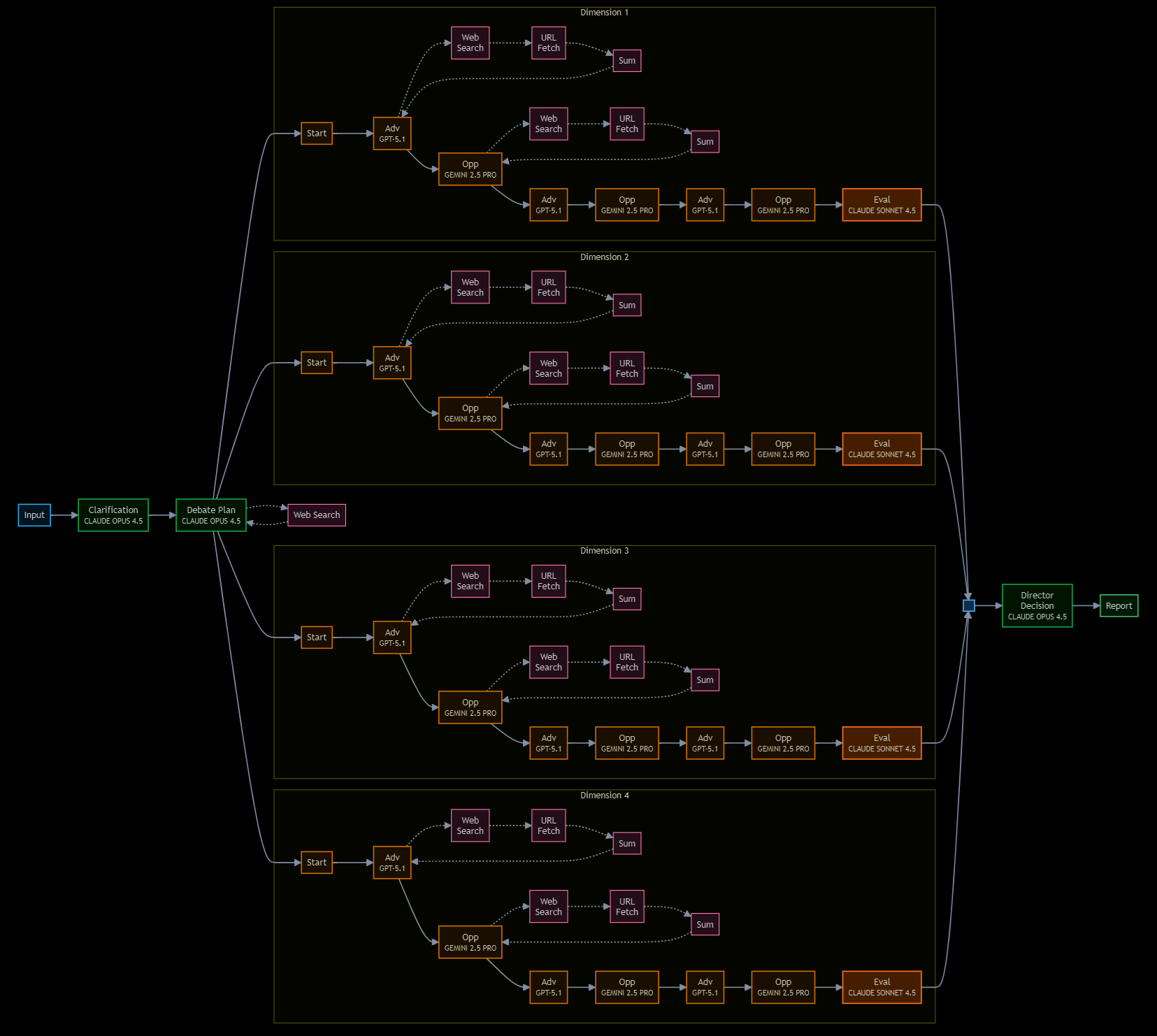
arbitrIQ's architecture draws on convergent findings from decision science, intelligence analysis, epistemology, and machine learning research.
Adversarial collaboration
When researchers with opposing hypotheses design experiments together, they produce stronger evidence than either would alone. The disagreement becomes a methodological asset, not a social liability.
arbitrIQ operationalizes this principle: the Advocate and Opposition are structurally prevented from converging, forcing genuine engagement with the strongest form of each position.
Kahneman, D. (2003). "Experiences of Collaborative Research." American Psychologist, 58(9), 723–730. Mellers, B. et al. (2001). "Do Frequency Representations Eliminate Conjunction Effects?" Psychological Science, 12(4), 269–275.
Structured Analytic Techniques
Intelligence agencies developed formalized methods — devil's advocacy, Team A/Team B analysis, Analysis of Competing Hypotheses — precisely because unstructured expert judgment systematically underperforms structured dissent under conditions of complexity and uncertainty.
arbitrIQ's dimension-by-dimension debate is a computational implementation of these techniques, applied at a scale and speed that human teams cannot sustain consistently.
Heuer, R.J. (1999). Psychology of Intelligence Analysis. CIA Center for the Study of Intelligence. U.S. Government (2009). A Tradecraft Primer: Structured Analytic Techniques for Improving Intelligence Analysis.
The Diversity Prediction Theorem
Collective error equals average individual error minus prediction diversity. This is not a heuristic — it is a mathematical identity. Aggregate accuracy improves with diversity of judgment, even when individual judges are imperfect.
arbitrIQ exploits this directly: independently-trained models with different architectures, training data, and reasoning patterns produce structurally diverse assessments. The ensemble is provably more accurate than any single member.
Page, S.E. (2007). The Difference: How the Power of Diversity Creates Better Groups, Firms, Schools, and Societies. Princeton University Press. Surowiecki, J. (2004). The Wisdom of Crowds.
Sycophancy and confirmation bias in LLMs
Large language models exhibit systematic sycophantic behavior: they tend to agree with the user's stated position, even when that position is wrong. Single-model interactions amplify the user's existing priors rather than challenging them.
arbitrIQ's adversarial structure is specifically designed to defeat this failure mode. The Opposition agent has no access to the user's preferred outcome — its mandate is to find weaknesses regardless of the user's expectations.
Perez, E. et al. (2023). "Discovering Language Model Behaviors with Model-Written Evaluations." Findings of ACL. Sharma, M. et al. (2024). "Towards Understanding Sycophancy in Language Models." ICLR 2024.
Cognitive biases and judgment noise
Human decision-making is distorted by two distinct and compounding failures. First, cognitive biases — confirmation bias, anchoring, overconfidence, loss aversion — are not random errors but predictable structural deviations. Under uncertainty, intuitive reasoning (System 1) dominates analytical thinking (System 2), producing coherent but often incorrect narratives. Second, even when bias is controlled for, human judgment suffers from noise: different experts given identical information routinely reach different conclusions, driven by context dependence, framing effects, and individual interpretation.
arbitrIQ addresses both failures simultaneously. Bias is countered by externalizing judgment across independent agents — no single cognitive frame can dominate. Noise is countered by enforcing a consistent evaluative architecture: every decision passes through the same structured protocol, eliminating arbitrary variability while preserving genuine disagreement.
Kahneman, D. (2011). Thinking, Fast and Slow. Farrar, Straus and Giroux. Kahneman, D., Sibony, O. & Sunstein, C.R. (2021). Noise: A Flaw in Human Judgment. Little, Brown Spark.
Expert prediction failure and cognitive diversity
Long-term studies of expert predictions demonstrate that domain experts perform only marginally better than chance in complex, uncertain environments — and that confidence is inversely correlated with accuracy. The mechanism is not lack of intelligence but overreliance on single explanatory frameworks and resistance to updating beliefs. Tetlock's taxonomy clarifies the solution: "foxes," who draw on multiple models and adapt their reasoning, consistently outperform "hedgehogs," who rely on a single overarching theory. The critical variable is not expertise but model diversity and epistemic flexibility.
arbitrIQ operationalizes this finding by design. Its multi-agent architecture enforces fox-like reasoning: competing structured arguments drawn from distinct analytical frameworks, with no single perspective able to dominate the decision process. Dependence on individual expertise or authority is replaced by structured adversarial engagement.
Tetlock, P.E. (2005). Expert Political Judgment: How Good Is It? How Can We Know? Princeton University Press. Tetlock, P.E. & Gardner, D. (2015). Superforecasting: The Art and Science of Prediction. Crown.
AI safety via debate
Irving, Christiano, and Amodei (2018) proposed that AI systems can be made more truthful by having them debate each other under human judgment. Their key insight: it is easier for a human to judge a debate than to find the truth independently. A strong debater cannot win by lying if the opponent can expose the lie.
arbitrIQ applies this principle to strategic decision-making. The decision-maker doesn't need to be an expert in every dimension — they need to see the strongest arguments from both sides and assess which survived challenge.
Irving, G., Christiano, P. & Amodei, D. (2018). "AI Safety via Debate." arXiv:1805.00899.